记一次JVM老生代增长过快问题排查
临近双11,大家都忙着发布各种优化版本,程序猿手起键落,满意的敲下最后一个回车键,心里想着这就是双十一最终版了,然而不知道等着他的是下一个双十一最终版……
版本上线后,观察了几天,程序猿发现一个异常现象,之前一直非常平稳的JVM老生代突然在上线后以有了明显的增长,而且是持续的增长。于是开始了这次老生代过快增长的问题排查……
揪出导致老生代快速增长的对象分析内存对象
先得找个好用的工具,唯品会开源的JVM工具箱vjtools是个不错的选择,可以将JVM新老生代的各个对象实例个数和大小的Histgram打印出来。
想看出老生代里是什么对象在不断增长,使用vjtools其中的vjmap分别dump两天的老生代对象实例出来。 第一天的dump:
#num #all count/bytes #old count/bytes #Class description
-----------------------------------------------------------------------------------
1: 102/ 1k 102/ 1k $Proxy22
2: 7073/ 283k 6403/ 258k boolean[]
3: 200073/ 157m 85594/ 135m byte[]
4: 493/ 26k 137/ 4k byte[][]
...
60: 365800/ 22m 357186/ 21m com.mysql.jdbc.ConnectionPropertiesImpl$BooleanConnectionProperty
61: 86800/ 5m 84756/ 5m com.mysql.jdbc.ConnectionPropertiesImpl$IntegerConnectionProperty
62: 3100/ 193k 3027/ 189k com.mysql.jdbc.ConnectionPropertiesImpl$LongConnectionProperty
63: 9300/ 653k 9081/ 638k com.mysql.jdbc.ConnectionPropertiesImpl$MemorySizeConnectionProperty
64: 127100/ 7m 124107/ 7m com.mysql.jdbc.ConnectionPropertiesImpl$StringConnectionProperty
65: 3100/ 3m 3027/ 3m com.mysql.jdbc.JDBC4Connection
66: 3126/ 97k 3027/ 94k com.mysql.jdbc.JDBC4DatabaseMetaData
67: 990/ 239k 924/ 223k com.mysql.jdbc.MysqlIO
68: 2927/ 68k 2854/ 66k com.mysql.jdbc.NetworkResources
69: 3100/ 96k 3027/ 94k com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference
从这份dump中发现JDBC4Connection这个类有些奇怪,程序里是用了连接池的,但这里的连接实例个数却有3027个,远远超过连接池配置的最大连接数,带着这个疑问,再看看第二天的dump:
#num #all count/bytes #old count/bytes #Class description
-----------------------------------------------------------------------------------
1: 102/ 1k 102/ 1k $Proxy22
2: 8407/ 336k 8017/ 321k boolean[]
3: 196962/ 174m 88444/ 153m byte[]
4: 512/ 27k 190/ 5k byte[][]
...
60: 462088/ 28m 452412/ 27m com.mysql.jdbc.ConnectionPropertiesImpl$BooleanConnectionProperty
61: 109648/ 6m 107352/ 6m com.mysql.jdbc.ConnectionPropertiesImpl$IntegerConnectionProperty
62: 3916/ 244k 3834/ 239k com.mysql.jdbc.ConnectionPropertiesImpl$LongConnectionProperty
63: 11748/ 826k 11502/ 808k com.mysql.jdbc.ConnectionPropertiesImpl$MemorySizeConnectionProperty
64: 160556/ 9m 157194/ 9m com.mysql.jdbc.ConnectionPropertiesImpl$StringConnectionProperty
65: 3916/ 4m 3834/ 4m com.mysql.jdbc.JDBC4Connection
66: 3933/ 122k 3834/ 119k com.mysql.jdbc.JDBC4DatabaseMetaData
67: 1266/ 306k 1200/ 290k com.mysql.jdbc.MysqlIO
68: 3697/ 86k 3615/ 84k com.mysql.jdbc.NetworkResources
69: 3916/ 122k 3834/ 119k com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference
两份dump对比,不难发现老生代里明显增长的对象就是这个JDBC4Connection(其他几个都是和这个类相关引用的)。
到底是哪里来的这些数据库连接呢?
注:这里采用连接池是c3p0, 版本是c3p0-0.9.5-pre8
紧跟用jmap将整个heap dump下来,通过MAT进行分析,JDBC4Connection这个对象一共有3792个实例,占用了100多M内存。

其中一个实例的GC Root Path: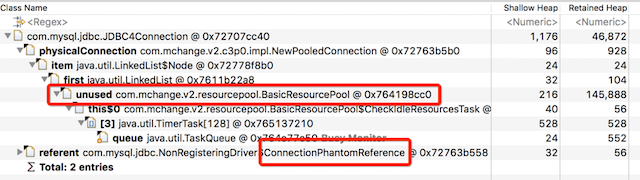
可见它被两个对象引用,一个是连接池BasicResourcePool的unused成员变量,一个是MySQL JDBC Driver的ConnectionPhantomReference,跟踪到源码中看看:
BasicResourcePool.java
/* all valid, managed resources currently available for checkout */
LinkedList unused = new LinkedList();
可见unused对象是连接池里的正常可用的连接。
NonRegisteringDriver.java
protected static void trackConnection(Connection newConn) {
ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl) newConn, refQueue);
connectionPhantomRefs.put(phantomRef, phantomRef);
}
这个虚引用是在JDBC Driver在构造connection时用来track这个connection的,在被GC回收前做一些clean up(释放资源)的事情,所以每个connection被构造出来后,都会被track,这是Driver为了防止有资源随着连接回收而未释放的手段。
可见,这个JDBC4Connection实例是堂堂正正的连接池里的连接实例,呆在老生代是理所当然的。
再来看另一个:
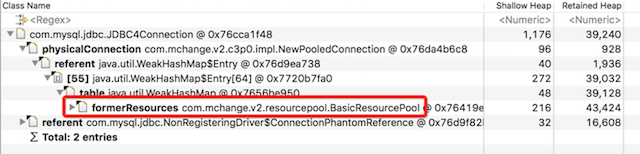
这个实例除了ConnectionPhantomReference引用外,还有一个也是连接池BasicResourcePool里的对象:formerResources,顾名思义:曾经在连接池里呆过的对象。
再检查其他的JDBC4Connection实例的GC Root Path,大部分都是第二个这种,被formerResources引用到的。
看到这里,基本已经清晰了,这些多出来的连接对象,应该是曾经被连接池里创建出来,用完后被抛弃掉的连接,被放到formerResources,这些对象熬过了几轮YGC,到了老生代,等着被老生代GC回收的”退休”对象。
真相渐渐浮出水面
继续跟进加入formerResources的相关代码:
private void removeResource(Object resc, boolean synchronous){
...
unused.remove(resc);
destroyResource(resc, synchronous, checked_out);
addToFormerResources( resc );
asyncFireResourceRemoved( resc, false, managed.size(), unused.size(), excluded.size() );
...
}
private void cullExpired(){
...
if ( shouldExpire( resc ) )
{
if ( logger.isLoggable( MLevel.FINER ) )
logger.log( MLevel.FINER, "Removing expired resource: " + resc + " [" + this + "]");
target_pool_size = Math.max( min, target_pool_size - 1 ); //expiring a resource resources the target size to match
removeResource( resc );
}
...
}
public Object checkoutResource( long timeout ){
Object resc = prelimCheckoutResource( timeout );
...
}
private synchronized Object prelimCheckoutResource( long timeout ){
...
Object resc = unused.get(0);
...
else if ( shouldExpire( resc ) ){
removeResource( resc );
ensureMinResources();
return prelimCheckoutResource( timeout );
}
}
重点关注removeResource这个方法,这个是连接池管理连接的一个重要方法,大致浏览了下调用它的地方,注意到cullExpired和checkoutResource这两处:
-
cullExpired这个方法是c3p0的一个定时器里执行的方法,用来检查过期连接的,如果配置了相关的连接池参数(max_resource_age,max_idle_time,excess_max_idle_time,destroy_unreturned_resc_time),就会对过期连接进行清理;再结合应用的配置,maxIdleTime设置了1800秒,结合代码逻辑,c3p0默认会1800/4=450秒一次定时对idle连接进行
连接池过期检查,若连接过期(空闲了1800秒),则会被remove,被加入到formerResources中,如果最后剩下的idle连接超过或小于minIdle的连接数,也会相应的进行缩减(shrink)或者扩充(explode)连接池的连接,达到minIdle个连接为止。有同学可能会问:“如果设置了minIdle和idleConnectionTestPeriod,这里的连接有keep alive,是否能逃过被清理的检查?”
回答是:“无法逃过,idleConnectionTest是维持连接池的idle连接和MySQL之间的心跳,防止MySQL server端踢掉应用的连接”,而前面提到的
连接池过期检查则是c3p0对连接归还后是否长时间没被再次借出为依据来判断连接是否已过期。”所以,即时是静静地呆着啥也不干,若配置了过期检查参数,这些keep alived的连接也会被认为过期而清理掉,然后重新生成一批新的,但啥也不干的时候,YGC也会很久一次,所以这些定期被清理掉的连接很可能熬不到老生代就被YGC回收了。
-
checkoutResource则是从连接池中获取连接的方法,从代码中可以看出每次获取连接时,都会对该连接进行过期检查的校验,同样还是上面那些参数,比如配置了maxIdleTime是1800秒,检查时若发现连接上次借出归还后超过1800s没有再次被借出,则认为连接已过期,调用removeResource,将连接加入到formerResources中。最后,结合应用对MySQL的调用场景:数据先从缓存(Redis)中获取,若发生异常,则回源MySQL。优化版的改动增加了回源MySQL的概率,所以,若是已经过期的连接,之前是定时450秒做一次检查,也就是可能会等450秒才被remove,然后再次生产新的连接;结果现在,可能没到450秒,而是通过checkout的同时就做了检查,加快了过期连接的失效和创建新连接的速度,导致formerResources里的”退休”连接变多,最终加快了老生代的增长。
如何解决
直接去掉maxIdleTime的配置,这个并不影响连接保活心跳,c3p0里对连接保活是在另外一个线程进行的,只要配置了
idleConnectionTestPeriod这个参数即可。双11后的更新
从这个具体的问题中跳出来,其实这是一类问题:持久化对象在JVM中的存活生命周期问题,连接池对象,本地缓存对象都是,这些对象存活时间久,处于JVM的老生代中,应用希望尽可能的重用它们,但若结合具体场景的配置或使用不合理,导致这些对象并未最大化被重用,比如上面提到的过期检查导致不断有新的对象被创建出来,因为是持久化对象,很容易就进入到了老生代,霸占了资源。
同样的问题,JedisPool也存在,双11刚过,在流量高峰期,发现应用的老生代不断涨:
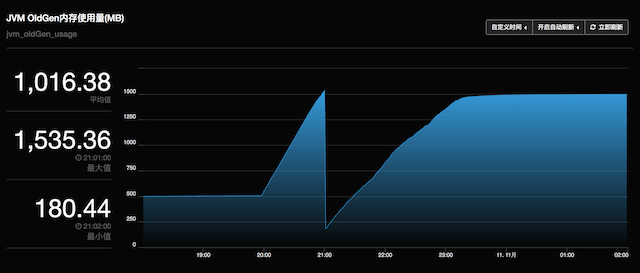
很明显,在晚高峰20:00开始前,老生代是很安静的,从买买买开始,就不正常了,直到0点过后又恢复平静。
一样的思路找下去,发现也是同样的问题,这是JedisPool默认的配置:
public class JedisPoolConfig extends GenericObjectPoolConfig { public JedisPoolConfig() { // defaults to make your life with connection pool easier :) setTestWhileIdle(true); setMinEvictableIdleTimeMillis(60000); setTimeBetweenEvictionRunsMillis(30000); setNumTestsPerEvictionRun(-1); } }每30秒进行一次扫描,如果发现有idle超过60秒的连接,则进行清除,若少于minIdle个连接,则再创建新的。
而清除掉的连接若未及时的被YGC掉,就会溜进老生代。再看看这段时间YGC的频率:
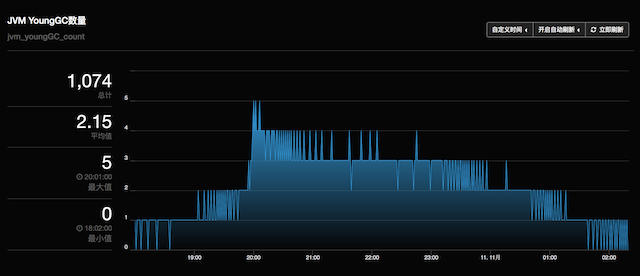
从20:00开始到0点,每分钟YGC 3-4次,而JVM配置的
-XX:MaxTenuringThreshold=4,所以idle的连接被清除掉后,再创建出来新的连接,到1分钟后的下次检查到过期期间,很容易熬过4次YGC,晋升到老生代。为什么高峰期还有idle的连接,配置的minIdle=8,然而Redis的响应太快,1个连接就可以轻松处理>1000QPS的请求量,再加上100个redis实例,每个实例1个连接,即可处理10WQPS(若请求是均匀散落到redis上),所以在高峰期,仍然有部分的连接是idle的。
怎么解决呢?继续看代码:
@Override public boolean evict(EvictionConfig config, PooledObject<T> underTest, int idleCount) { if ((config.getIdleSoftEvictTime() < underTest.getIdleTimeMillis() && config.getMinIdle() < idleCount) || config.getIdleEvictTime() < underTest.getIdleTimeMillis()) { return true; } return false; }在commons-pool的过期策略中发现
minEvictableIdleTimeMills有一个孪生兄弟softMinEvictableIdleTimeMillis(即idleSoftEvictTime),如果idle的时间超过这个配置值,且当前idle的连接个数比minIdle要多,则进行清除。所以解决办法是配置
minEvictableIdleTimeMills=-1,softMinEvictableIdleTimeMillis=60000,这样就不会对minIdle的连接进行清理,只有当连接数超过minIdle后,才进行清理工作。优化效果
[优化版本] 12小时老生代变化趋势:
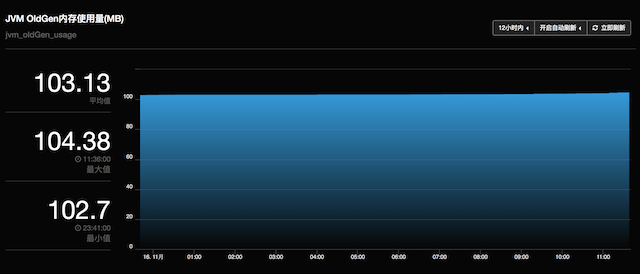
[未优化版本] 12小时老生代变化趋势:
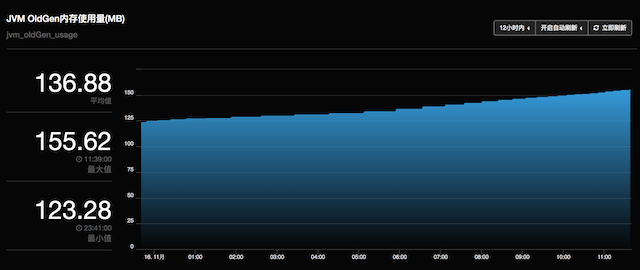
除了老生代增长速度平缓了,YGC的停顿时间也有明显改善:
[优化版本] gc.log:
2017-11-16T09:54:04.202+0800: 68118.496: [GC 68118.496: [ParNew: 1680716K->2934K(1887488K), 0.0074850 secs] 1786721K->108960K(3984640K), 0.0077080 secs] [Times: user=0.07 sys=0.00, real=0.01 secs][未优化版本] gc.log:
2017-11-16T09:53:26.996+0800: 67675.370: [GC 67675.370: [ParNew: 1718298K->39709K(1887488K), 0.0267350 secs] 1870355K->192401K(3984640K), 0.0269810 secs] [Times: user=0.40 sys=0.00, real=0.02 secs]避免了JedisPool里minIdle中池化对象的不断创建/销毁动作,YGC完后剩余的对象少了很多,YGC的搬迁工作减轻不少,所以停顿时间也大幅缩短了。