深度学习在用户画像标签模型中的应用
最近一段时间都在学习深度学习,想着在用户画像标签模型中看能不能用上,终于,用了一个多月的时间,结合实际的场景和数据,搭建了一套“孕妇标签”的深度学习模型。这篇文章重点介绍了在用户画像标签模型中运用深度学习建模的过程中,我们遇到的一些问题,以及其中的一些体会和思考,对于深度学习的一些基础概念和模型,文章没有过多的介绍。另外,自己也属于深度学习的入门阶段,若有理解有误的地方,欢迎大家指正。
什么是用户画像标签
基于用户事实数据,进行一定抽象后的用户特征表示
拿电商为例,用户的购物性别,年龄,消费能力等都是用户画像的标签。这些标签能帮助我们理解用户,将用户进行归类,进一步进行个性化运营,例如针对高消费人群,那我们可以展示比较有品味的服装给用户。
标签建模的方法
标签建模有什么方法?可分为两大类:
-
人工建模
凭借经验,对标签定义一个数据描述口径,通过大数据ETL跑出标签结果,再逐步通过调整口径达到运营可接受的模型。
-
机器建模
通过机器对标签样本数据的多维度学习,建立机器自学习的标签模型,可通过对样本数据的调整以及模型结构及参数的调整来逐步优化模型。
两种建模方式各有优缺点,这里介绍如何运用深度学习进行机器建模。
下面以“孕妇标签”为例(电商场景下),我们是怎样一步步完成深度学习建模的。
简陋的模型
一开始思路很简单,将用户的各个品类购买行为做为模型训练的特征,并通过对品类划分中挑出和孕妇明显相关的品类(例如孕期护理,孕妇装,高跟鞋,彩妆等),通过某些品类的购买行为筛选出训练正负样本,例如按一年统计用户对各个品类的购买次数,若孕妇相关品类购买次数超过5次,则标识为正样本,若高跟鞋,彩妆类购买次数超过5次,则标识为负样本。
正负样本,模型训练需要的特征数据都有了,最简单的就是构造一个浅层神经网络模型,将数据丢给模型,看看模型能否自我训练学习,这就是模型最初的样子:
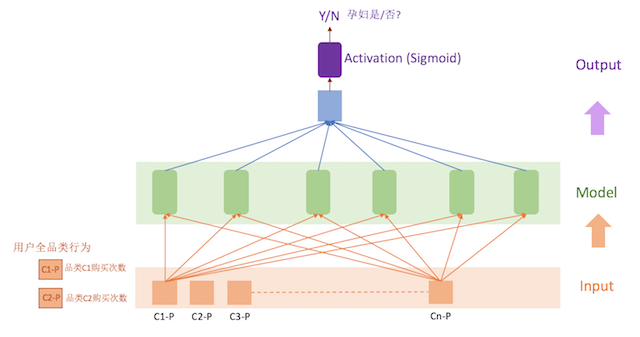
这个版本的模型直接用Keras构造,非常简单,也可以直接看到实时训练的情况。准备了5万的样本训练数据,大概几分钟就可以发现模型的Training accuracy和Validate accuracy都达到了0.9以上,可以试试模型的效果,但要再找出一批已知是否孕妇的数据,是个大难题,所以比较直接的就是找了几个(女)同事的帐号,虽然测试数量少,但比较有代表性,很容易发现模型的问题: 对于几个月前是孕妇,现在已经是妈妈的情况,没有准确的识别出来。想想,因为模型输入的数据是过去一年的购买记录,模型无法感知数据在时间维度上的变化。
时序模型
由于孕妇标签的时间敏感性,模型中需要考虑时间维度,比如6个月前有购买过孕妇类,最近2个月已经不再买了,而是开始买婴幼品类的商品,这个说明现在已经不再是孕妇了,应该打上新生妈妈的标签了。
因此,首先在模型的特征维度上需要将一年的购买行为按时间间隔(月)拆开,同时将用户的购买行为数据放在一个时间轴上,这样可以提供更立体的特征数据给模型训练,于是我们选用了可以感知时序数据的RNN模型,对用户某段短时间内的购买行为综合分析学习,这样模型更容易准确地判断出孕妇标签。
比如,用户购买平底鞋这个行为,一般情况下,对孕妇标签的判断没有太大的作用,但如果用户购买平底鞋的时候,还买了孕妇裤,这就不同了,购买平底鞋这个行为就变得和孕妇行为相关了,和标签结果就有一定的相关性。就是因为加上用户前后购买行为这个Context,而让数据更立体,更丰富,模型对标签的判断也就更准确。
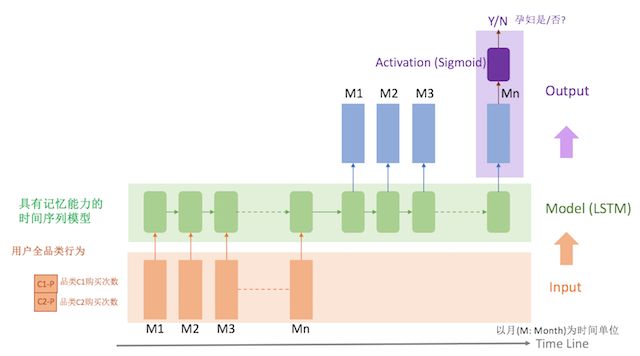
模型的特征是用户每个月对各个品类的购买次数,比如我们对最近18个月的,2000个品类进行统计,得到18*2000的矩阵,作为一个用户的特征表示,所以模型的inputs维度是:user_num * months * categorys (e.g. 10000 * 18 * 2000),output targets维度是:user_num * 1 (e.g. 10000 * 1)
模型采用LSTM,对LSTM的最后一个output通过sigmoid映射到[0,1]后和target对比,计算得出cost函数。
模型训练完后,再用测试数据校验了下,已经可以准确区分出新生妈妈和孕妇了。
但这个模型的输入特征不够丰富,用户的行为除了购买之外,点击行为也是放进来,让学习维度更加丰富。
多时序模型
从用户的浏览->点击->购买这个转化漏斗可以知道,用户的点击行为远比购买行为更频繁。以月为单位,一个用户在某个品类的购买次数一般为1次,很少超过10次。但点击不同,如果以月为单位统计,点击的数量会很大,这样会有什么问题?
假设按自然月统计,如果一个用户在1号那天就对某个品类点击次数达到10次,我们知道用户对这个品类是有偏好的,但如果放到1个月统计这个维度,10次可能还没达到模型认为有强相关的程度。换句话说,就是模型无法实时感知到用户的偏好变化。
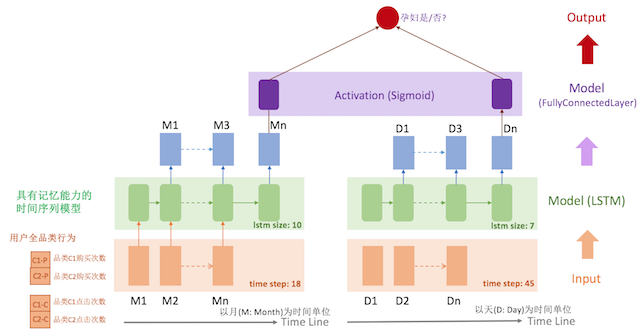
所以,针对点击行为,我们得采用以天为单位统计用户在各个品类下的点击次数,作为模型的输入。这样就出现了购买行为和点击行为的两套时序模型,他们的时间维度不同,不能放在一套LSTM模型里,只能分开两套,再通过一层fully connected layer,将两套LSTM的输出作为这层的输入,得到最终的模型结果。
模型调优
结合点击和购买时序行为的模型,使用样本的筛选规则得到的数据,都可以准确的识别出结果,但模型的泛化能力如何,会不会overfit,由于缺乏更丰富的数据样本,并不好验证这点。
所以,对于模型的评估,我们采取人工伪造数据的方式来校验,比如将训练样本中的购买数据全部抹掉,这样用一份只有点击的数据来校验模型对点击行为的学习能力;再比如将训练样本中强孕妇相关品类的购买,点击数据抹掉,来验证模型对其他“潜在”的相关维度的学习能力。
值得一提的是,模型的训练样本是按照一定的规则进行人工筛选标注完成的,而筛选的条件同时也是模型的学习维度中的一部分,这意味着模型很容易学习到这些“人工设定”的规则,而忽略那些“潜在”的维度和结果之间的相关性。模型容易出现“Memorize more than Learning”,也就是缺失泛化能力。
如何提高模型的泛化能力:
- 减少Hidden Size,降低模型记忆单元数
- 增加Dropout,通过随机抹掉部分hidden layer的节点,类似通过让模型变得简单,同时通过将多个简单的模型的结果综合起来,达到提高泛化能力的目的
- 采用L2 Regularizer,通过对权重的惩罚,来提高模型泛化能力
- 提供更丰富的训练样本,让模型接触更多不一样的数据
体会和思考
-
深度学习模型更像一个黑盒子,无法通过因果关系进行逻辑推导,而只能通过不同的数据不断从外部试探,理解模型
-
人的很多特征都是会随着时间变化的,用户画像的标签建模是需要考虑好时间维度的数据
-
用户画像标签模型的数据样本获取成本大,通过规则筛选的数据,不够丰富,容易导致模型泛化能力差