GuavaCache在高并发场景下的应用
Guava是Google提供的一套Java工具包,里面内容的含金量非常高,强烈建议深入研究,这次要看的是Cache的部分,Guava Cache提供了一套非常完善的本地缓存机制,在Guava之前,JDK的concurrentHashMap是经常用做本地缓存的,因为能友好的支持并发,但它毕竟还是个Map,不具备缓存的一些特性,比如缓存过期,缓存数据的加载/刷新等。
Guava Cache知识点
高并发场景下如何使用
使用缓存,就存在缓存数据一致性的问题,和缓存数据的更新敏感度的问题,这个就是缓存的数据更新问题。
如果是分布式缓存,就另外涉及到分布式的数据一致性问题,这里仅针对本地缓存进行讨论。
针对本地缓存,更新方法有很多种,比如最常用的:
- 被动更新: 是先从缓存获取,没有则回源取,再放回缓存;
- 主动更新: 发现数据改变后直接更新缓存(在多机环境下,不好保证多机数据同时更新)
在高并发场景下,被动更新的回源是要格外小心的,也就是雪崩穿透问题: 如果有太多请求在同一时间回源,后端服务如果无法支撑这么高并发,容易引发后端服务崩溃。
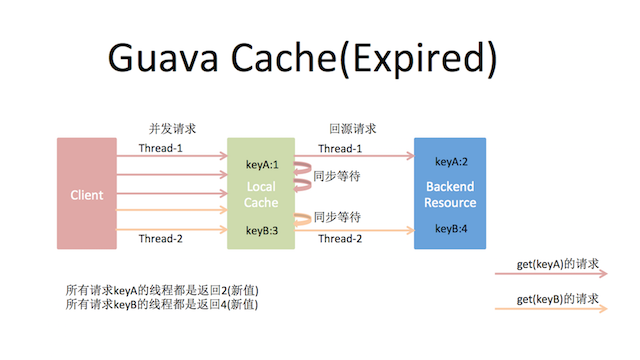
这时Guava Cache上场了,Guava Cache里的CacheLoader在回源的load方法上加了控制,对于同一个key,只让一个请求回源load,其他线程阻塞等待结果。同时,在Guava里可以通过配置expireAfterAccess/expireAfterWrite设定key的过期时间,key过期后就单线程回源加载并放回缓存。
这样通过Guava Cache简简单单就较为安全地实现了缓存的被动更新操作。
为什么是”较为安全”呢?因为如果同一时间仍有太多的不同key过期,还是会有大量请求穿透缓存而请求到后端服务上,仍然有可能使后端服务崩溃,有什么办法解决这个问题呢?
1.将key的过期时间加个随机值,避免大家一起过期(前提是对业务不影响),
2.自己控制回源的并发数,即使有一万个key要更新,也只让100个可以回源,其余的9900个等着,(可以通过Guava的Striped实现)
3.在过期前主动更新,更新完成后将过期时间延长
4.大家请继续大开脑洞想...
另外,如果对刚才说的对于同一个key,只让一个请求回源,其他线程等待觉得还不爽,虽然对后端服务不会造成压力,但我的请求都还是blocked了,整个请求还是会被堵一下。
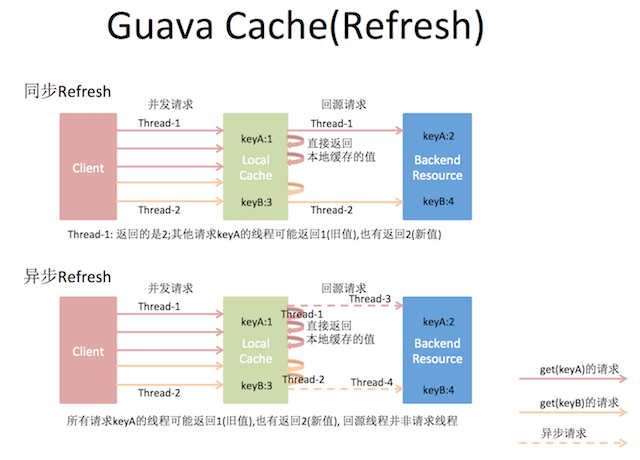
别急,Guava Cache还提供了一个refreshAfterWrite的配置项,定时刷新数据,刷新时仍只有一个线程回源取数据,但其他线程只会稍微等一会,没等到就返回旧值,整个请求看起来就比较平滑了。为什么又是“比较平滑”呢?因为默认的刷新回源线程是同步的,如果想达到全过程平滑的效果,可以将刷新回源线程做成异步方式。
这样数据的更新都是在后台异步做了,但这样也是有一定的代价的,比如过了刷新时间,仍可能拿到旧值,直到拿回数据更新缓存后才会返回新值。
因为这个refresh动作并不是主动发起的: 比如设置了5秒refresh一下,Guava的做法并不是真的每5秒刷一次,而是等请求到了之后,发现需要refresh时才会真的更新。所以,这一点需要注意,比如虽然设置了5秒刷新,但如果超过1分钟都没有请求(假设key没有过期),当1分零1秒有请求来时,仍有可能返回旧值。(有没有解决办法呢?)
以下是关于设置Expire过期和Refresh刷新(sync/async)两种方式,Guava Cache对请求回源的处理示意图:
一些其他方面的思考
本地缓存把对象搬进内存,提高访问访问能力,但同时也会带来内存管理方面的影响。比如缓存的对象若是一个“大”对象,缓存数据的更新可能会带来什么问题?老年代过快增长。有什么办法避免?可以考虑数据的更新方式做成按需(有变化)全量更新,或者甚至是增量更新。