Practise of Using Graphite
关于Graphite的介绍文档有很多,江南白衣的Graphite wiki已经写得很全面了,这篇文章就不会再更多的介绍Graphite了,而是从一个使用者的角度补充一些实际采用Graphtie收集业务数据时遇到的问题及解决办法1,通俗点说就是“我们曾经踩过的坑及填平方法”,额,有没有填平,还有待系统上线的考验。
我们用的graphite版本是0.9.12,最新的稳定版。
先大致介绍下我们最开始采用的Graphite部署模型,比较简单:
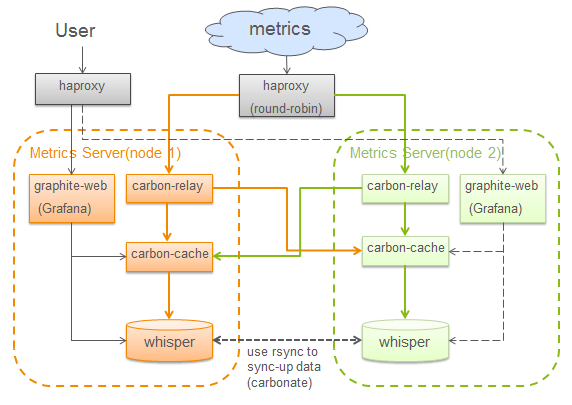
两套ative的graphite server,metrics由前端的haproxy做round-robin分发到两台graphite server,carbon-relay将数据双写到两边的carbon-cache,保证两边的graphite server数据一致,这是最简单的HA方案,对于一台server failover的情况,recover可以通过carbonate提供的sync脚本对两边whisper文件进行同步。用户的访问查询请求,也是经过haproxy随机分发到某一台graphite server查询,由于两边的数据是一致的,所以graphite server查本地whisper和carbon-cache就够了。
目前的这套部署,对已有的需求完全可以满足了。但剧情的需要,有了新的需求:存储并可通过dashboard展现更大的traffic的数据:每秒8万的metrics数据。 对于这样的需求,我们一开始发现下面几个问题:
- 数据存储空间过大
- 对于普通磁盘,每秒8万的metrics数据写入会导致disk IO一直100%被占用
- dashboard上查询比较多metrics的统计数据时非常慢
那我们来逐个看看这些问题:
数据存储空间过大
这个问题很容易解决,首先你得知道whisper的数据存储结构2,每个datapoint需要的存储空间是12bytes,而且whisper的数据是预占式的,意味着你不需要等到有1年的数据之后再看大小,而是可以直接根据定义的metrics retention算出来的,比如1min:1d,这样的存储精度算出来一个metric需要1440*12=17280bytes。所以可以根据这个计算方式,结合实际磁盘的大小,对metric精度的要求重新衡量下,什么样的精度是合理的。
对于普通磁盘,每秒8万的metrics数据写入会导致disk IO一直被100%占用
如果用SSD,测试每秒8万的metrics数据写入完全没有压力,但没钱用SSD,普通磁盘怎么办呢?graphite在当初设计时就考虑到了这点3, 于是有了carbon-cache,它的作用就是将同一个metric的所有datapoint先缓存起来,一定数量后再一次刷到磁盘,从而减少磁盘频繁寻道的消耗,提高磁盘利用率,而对于查询的请求,会同时查磁盘的whisper数据和cache里缓存的数据,最后汇总返回。同时carbon-cache还为了防止磁盘被全占用而影响其他的IO操作而加了一个MAX_UPDATES_PER_SECOND的配置项,可以适当降低这个值,使IO的usage降下来,带来的影响则是会有更多的datapoint被缓存在cache里了,这个会有什么负作用呢?如果在这时重启的话,需要将shutdown命令的等待时间设长一些,比如10min,这样让缓存在cache里的数据都可以被写到磁盘里,否则会丢失一部分还在缓存中而没能来得及写到磁盘里的数据。
dashboard上查询比较多metrics的统计数据时非常慢
这个问题的根源whisper的存储方式,因为whisper是按照一个metric,一个文件来存储它的datapoint,所以如果查询涉及到的metrics量太多,则需要将这些whisper文件逐个打开查询。所以对这个问题的fix也是最棘手的,有两个思路:
-
减少需要查询的metrics数量:一般查询都是对metrics做一些统计,那么可以通过carbon-aggregator在收到metrics时预先计算一些统计值出来,当作新的metric存下来:比如对这样的metric数据:metrics.<node>.cpu.load_average.min,统计所有node的cpu load_average,那么可以通过aggregator先统计好一个metrics.allnode.cpu.load_average.min的metric,然后dashboard那就直接查这个metric的值,而不需要做一次metrics.*.cpu.load_average.min的查询计算。当然了,并不是说需要对所有的需要做统计的字段都预先处理,如果node只有几个的话,预统计的意义也不大,反而可能会带来其他的问题(见下面的issue)。
-
将metrics做垂直/水平分区,减少每个graphite server上放的metrics数量(有待进一步的验证)
我们采用第一个思路,发现使用carbon-aggregator后,查询的时间缩短了很多,从之前30s缩减到10s内。但这个优化也费了我们很长时间,才最终得到了一个满意的结果。
先看看我们的需求: 我们有一类这样的metrics:metrics.<node>.<app>.<api>.<status>.count,然后需要在dashboard里可以根据app,api,status分别做过滤条件查看统计值(比如总和,Top5)。其中node是跑traffic机器的id,一般会有10台左右,app是application的id,数据量大概在1000左右,api数量大概在10以内,status是api的返回status code,比如HTTP Response里的status code.
于是,我们很容易想到,node的信息是不需要的,可直接通过carbon-aggregator聚合掉,于是我们就加了第一个aggregator,将node这个维度做次聚合,变成metrics.allnode.<app>.<api>.<status>.count,并将原始带有node信息的metrics都过滤掉(使用carbon的blacklist),这样后面处理的元数据就滤掉不少了,看起来生下来的事情就可以像搭建pipeline一样很happy的添加carbon-aggregator了,然后,app这一层也可以做一次聚合,因为app的量很大,同时我们也对api这个维度做了聚合,因为可以减少Top5 app的查询metrics量,也许有人会问,是不是把status那个维度也聚合了?这其实是个open question,我们的考虑是将api那层聚合后,dashboard的loading时间已经满足需求(<10s)了,如果将status也做聚合,当然可以将时间再缩短,但也会带来一个问题——aggregation-rules的配置复杂度增加,现在对app和api两层都做聚合,就需要配置3条rules:
metrics.allnode.
metrics.allnode.all.
metrics.allnode.all.all.
可以看到,如果把status也做聚合,则会有6条rules,这仅仅是对这一类的metrics的规则,我们还有其他类型的metrics需要类似的聚合,这样整个配置文件的复杂度会非常高(不易维护),而aggregator的实现是会让每个收到的metric对每条rules都匹配一遍的,效率的影响也需要考虑。因此,我们并没有把status那层也做聚合。
另外,对于graphite webapp,我们采用Gunicorn来搭建graphtie webapp的http server,注意Gunicorn启动时最好配置多个worker或者多thread,因为dashboard上一般会有多个graph,每个graph都会发送query的请求到graphite-web,由于django是单线程工作的,所以只要有一个graph的查询慢,其他的查询也会被blocking。
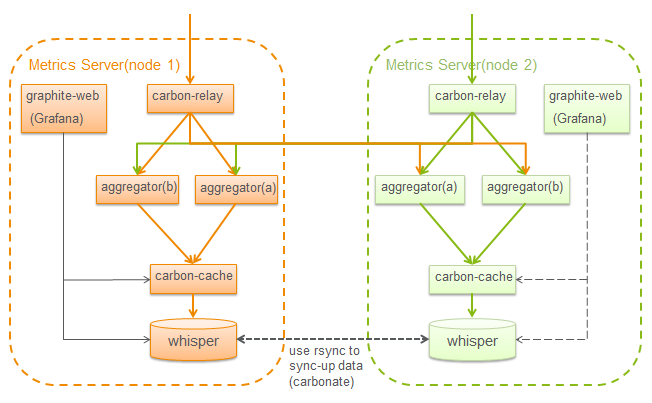
OK,我们的部署经过这个优化完后就变成了这样:
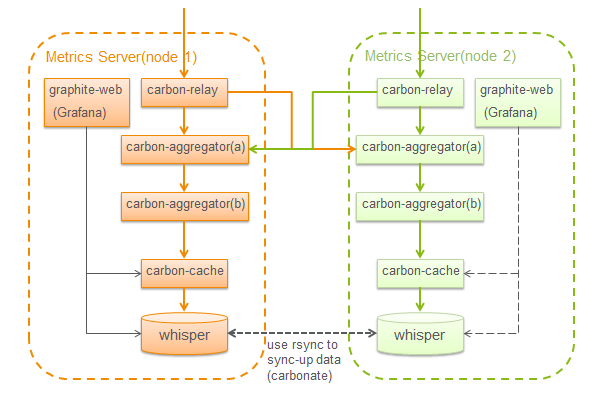
这样是不是就完了?按照正常剧情的发展,一般都会有些波折,我们也不例外,进一步的测试发现另一个问题:
graphite统计的数据比真实发送的数据少一半不止
这个问题在github上已经有人提了,fix也进了0.9.x和master的branch,大喜,手工打上patch,再跑,数据还是少……然后我们发现aggregator的cpu用到了100%,再查看carbon aggregator的代码,理解了MAX_AGGREGATION_INTERVALS这个配置(后面在讲carbon-aggregator工作原理时会再介绍),猜测可能是aggregator处理不过来(cpu 100%),导致处理滞后,部分数据被遗漏聚合,而导致统计数据比真实数据少,适当加大MAX_AGGREGATION_INTERVALS后,本以为数据就不会漏了,但更神奇的事情发生了:
graphite统计的数据比真实发送的数据多
遇到这个问题,就没有办法了,只能看代码+各种可能性的排查,最终定位到还是aggregator的问题,所以,我们还是先了解一下carbon-aggregator的工作原理吧:
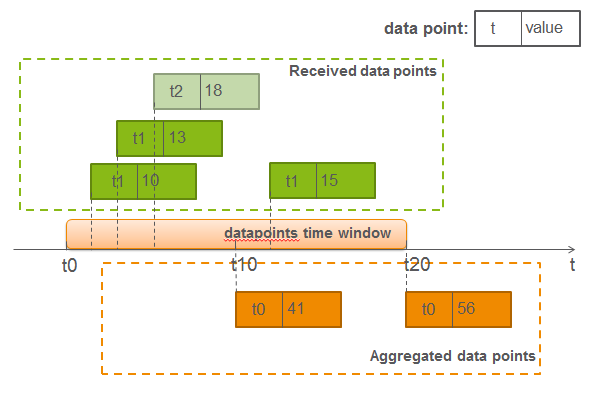
首先,我们假设配置的聚合频率是10s一次,聚合方式是求和(sum),t0, t10, t20这几个时间戳相差10s,而MAX_AGGREGATION_INTERVALS=2,也就是会保存做两次aggregation的时间长度的metrics(datapoints time window),超过这个时间长度(比如20s以前)的metrics,aggregator会将丢掉其aggregated的数据,意味着如果同样的metric key,同样的timestamp,在20s之后收到,再做aggregator时,是不会和之前丢掉的aggregated的数据再合并的,结合上面图例中的情况:
在t0和t10之间的10s内收到同一个metric的3个datapoints:(t1,10),(t1,13),(t2,18),在t10这个时间点到达时,carbon-aggregator就做一次aggregation,计算出来的结果会生产一个时间戳t0的新metric:(t0,41)。
然后在t10和t20之间又收到这个metric的datapoint: (t1,15),落在aggregation保留的metric时间窗口内,aggregator会继续之前的统计结果计算新的datapoint:(t0,56)。 所以这个datapoint才是最准确的aggregation结果。
所以,之前发现统计数据少了的原因就是因为有些datapoints处理滞后,落到了aggregation保留的时间窗口之外了,而导致第二次的计算的时候没有将第一次的结果统计进去。
那为什么统计数据会比实际多呢?还是看回这个原理图,还记得在前面我提到我们用了两个carbon-aggregator吗?第一个的统计结果会作为第二个的输入再统计,那么结合刚才的那个问题,如果有datapoint(比如图例中的(t1,15))在第一个aggregator的处理被滞后,会导致第一个aggregator做两次aggregation,生成(t0,41)和(t0,56)两个datapoints,而它们有同一个metric key,而且同一个timestamp(t0),但value分别是41和56,对于第二个aggregator(假设统计方式仍是sum),它会把这两个datapoint再次聚合(sum),得到的datapoint是(t0,97),而正确的结果应该是(t0,56),因为从原始的数据来看,统计结果应该是10+13+18+15,也就是56,这就是统计数据比实际数据多的原因了。
解决办法有两个:
方法一):避免用两个aggregator串行统计,而是使用一层平行的多个aggregator,统计结果直接发到carbon-cache,根据这个fix,carbon-cache会对同一个metric,同一个timestamp的多个datapoints按carbon-cache收到他们的时间倒序排列,取最近一次收到的结果作为这个metric最终的datapoint。这样,就可以保证即使aggregator做了多次聚合4,最终统计的结果也是正确的。那么,是用一个aggregator,对所有的metrics的聚合都由它来完成呢?还是分开多个aggregator,每个负责统计不同业务数据类型的metrics?用一个aggregator:整体架构简单,但处理效率低,用多个aggregator:架构复杂,但处理效率高5。所以如果metrics本身是可分类的,traffic又比较大,比如每秒上万的metrics,那么就应该考虑分多个aggregator的方案,因为aggregator的处理效率直接影响到数据统计的准确性,因为处理的延时,可能导致一些数据很晚才被统计,而且可能已经过了aggregator设置的datapoint time window。比如我们这样的情况,如果只用一个aggregator,datapoint time window设置50s,跑上几分钟的traffic后,统计数据就开始不准确了。但如果在traffic不大的情况下,用一个aggregator可以处理所有的聚合工作,只要不导致延迟处理的情况,也不会出现最终统计数据的不准确问题。这里也提到了类似的对于使用多个aggregator的建议和考虑,
注意:只要发现有aggregator的进程CPU占用率一直在100%徘徊,就是出现了延迟处理的情况,这时就需要:
-
拆分多个aggregator分担处理请求,
-
或者将aggregation interval的时间加大,比如从10s变成60s(如果10s和60s所需统计的metric key总量一样,才有改善的空间,当然前提是需求上可以忽略10s的统计值),相当于是给多些时间做aggregation,
-
或者采用carbon-c-relay,一个用C写的carbon,功能集包括了carbon-relay,carbon-aggregator和carbon-cache,由于是C实现,所以可以利用多核处理,效率大大提升,具体使用可以参考这里
方法二):仍然用两个aggregator串行统计,但第一个aggregator的datapoint time window设置为一次aggregation interval的时间,也就是MAX_AGGREGATION_INTERVALS=1,而后面接着的aggregator的datapoint time window需要设置大一些,这样做的目的?请看下图:
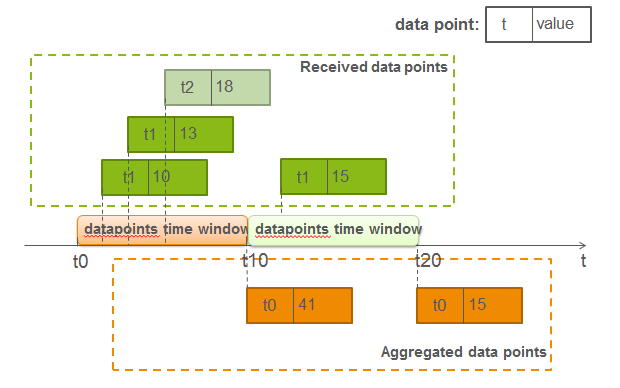
可以看到,经过第一个aggregator后,产生了两个datapoints(t0,41)和(t0,15),那么只要第二个aggregator的time window包含了t10时刻产生的(t0,41)和t20时刻产生的(t0,15),那么最终统计的结果仍然是正确的(t0,56)。
另外,这里给一个定义“好”的aggregation-rules的Tips:
尽量使aggregation后的metric key个数少,避免aggregation占用100%CPU
没有理解?没关系,我们看个例子:
对于这样两个的rules:
metrics.all.<app>.<api>.<status>.count (10) = metrics.*.<app>.<api>.<status>.count
metrics.<node>.all.<api>.<status>.count (10) = metrics.<node>.*.<api>.<status>.count
第一个是对node做聚合,这样产生的新metrics个数会很多,因为app的个数比较多;第二个对app做聚合,这样产生的新metrics个数不多,因为app这个个数多的维度被聚合成一个了,而其他维度的个数明显少于app的个数。所以第二个rule的开销低,但并不是说不能定义第一个rule,而是不能定义过多的这样的rules,比如这条是count,后面还接着有min, max等同样都是不对app做聚合的rules,导致太多新生产的metrics,而使aggregator忙不过来,因为可以理解为aggregator其实是会为每一个新的metric的聚合都准备一个线程处理的,这样metrics太多,需要准备的线程数太多了。
最后我们所选择的方案还是第一个(没有特别原因),所以,我们部署模型最终变成这样:
-
对于这里列出来的问题,如果你有其他的办法解决,非常欢迎留言分享或者email:neway.liu1985@gmail.com. ↩
-
详细可参考The Architecture of Graphite第7章. ↩
-
详细可参考The Architecture of Graphite7.6, 7.7两小节. ↩
-
aggregator做多次聚合是指对一个datapoint time window内收到的datapoints做了多次聚合,因为超过这个时间窗口的datapoint,会被重新统计,这样会统计值就不准确了,输出到carbon-cache再写到磁盘的数据也是不准确的。 ↩
-
一个carbon-aggregator就是一个处理进程,加上python的GIL限制,加多一个aggregator并行处理,整体的处理能力也就提高了。 ↩